Tag
#Aws

Upgrading to AWS Lambda Powertools for Python v2
Learn how easy it is to upgrade AWS Lambda Powertools to version.

Tracking Infrastructure with SSM and Terraform
Use AWS SSM Parameter Store to share resource references with other teams.

Close the Gate: Why You Need Egress Controls in your Security Groups
Open egress in your cloud environments is bad idea.

A Rube Goldberg Machine for Container Workflows
Learn how can you securely copy container images from GHCR to ECR.

Parameter Store vs Secrets Manager
Which AWS managed service is best for storing and managing your secrets?
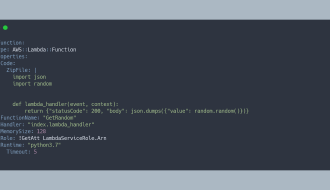
If You're not Using YAML for CloudFormation Templates, You're Doing it Wrong
Learn why you should be using YAML in your CloudFormation templates.

Logging Step Functions to CloudWatch
A quick guide on how to stream AWS Step Function logs to AWS CloudWatch.

AWS Parameter Store
Anyone with a moderate level of AWS experience will have learned that Amazon offers more …
Migrating AWS System Manager Parameter Store Secrets to a new Namespace
When starting with a new tool it is common to jump in start doing things. Over time you …