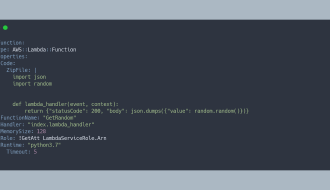
If You're not Using YAML for CloudFormation Templates, You're Doing it WrongBy | Jul 17, 2020Learn why you should be using YAML in your CloudFormation templates.